Next: Conclusions and Future Work Up: Analysis of Sample Transportation Previous: Scenario Performance Data and Contents
To evaluate different transit paradigms, we'd want to reduce the relationship between system design variables and performance metrics into a series of parametric equations. We could then compare the projected levels of investment necessary for infrastructure and operations under competing transit paradigms to meet similar performance goals.
We set up a factorial experiment to determine the impact of several design factors. By individually varying each independent variable and observing its effects on our performance metrics, we can establish correlations between our design inputs and system outputs across a variety of conditions.
The scenario generation script populates a full factorial directory tree of 144 scenarios using the following input values for each parameter of interest:
A post processing script collects the following output metrics (condensed forms of the histogram data in Section 5.5) and summarizes them into rows on a spreadsheet:
Each row of input and output data on the summary spreadsheet represents a different demand level and transit network configuration. We can then use this spreadsheet to generate several families of plots that characterize the performance impact of a range of design input variables. Each of these plots include data regression curves useful for highlighting correlations and for creating an approximate parametric model of transit system design. By applying data filters to the spreadsheet, we can quickly create several plots that compare the different major design paradigms.
We can use our factorial analysis to perform a quick comparison of design factors. In this case, we'd like to highlight some of the performance differences between a transit network with sequential routing and one built to accommodate express routes that can bypass intermediate stations.
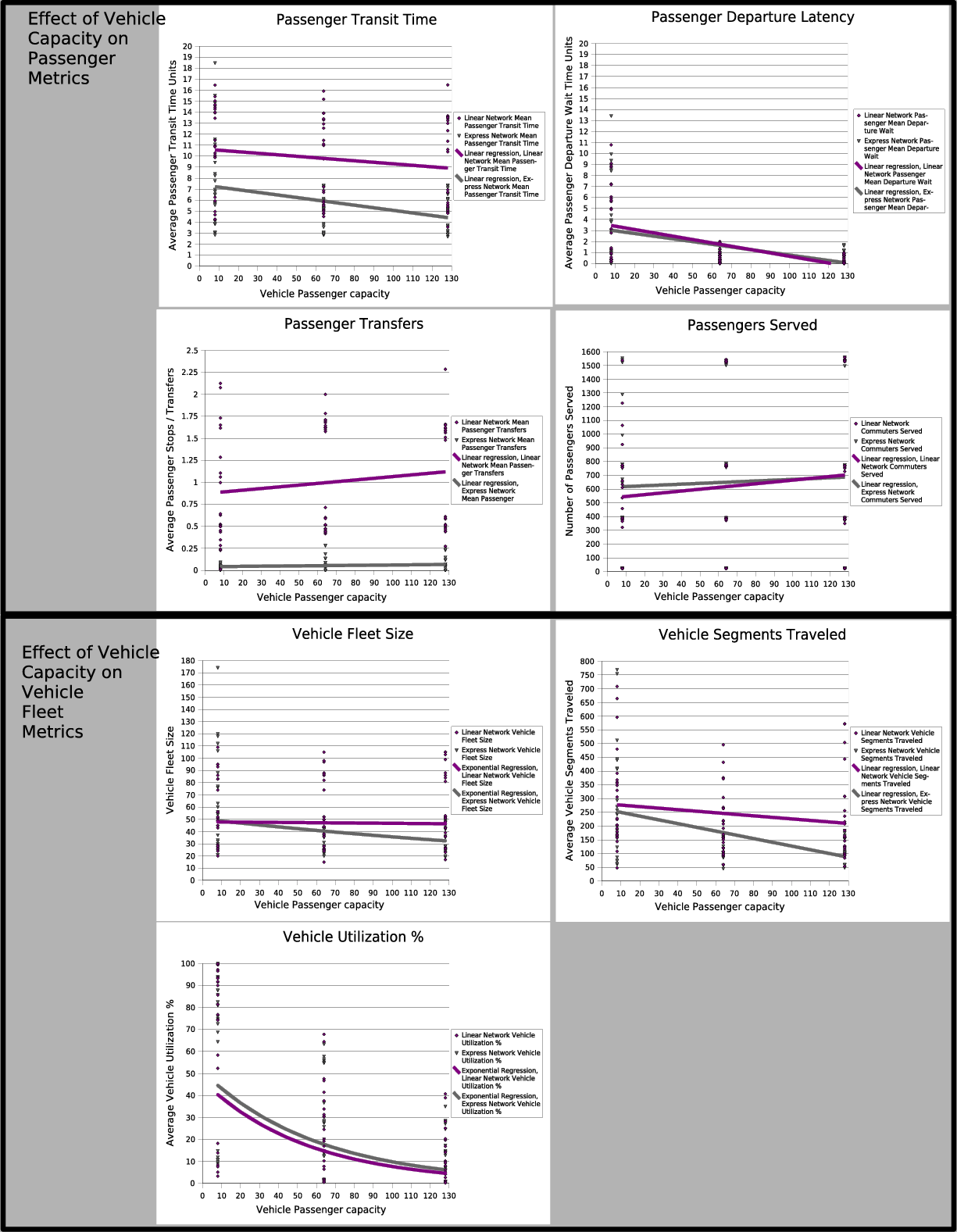
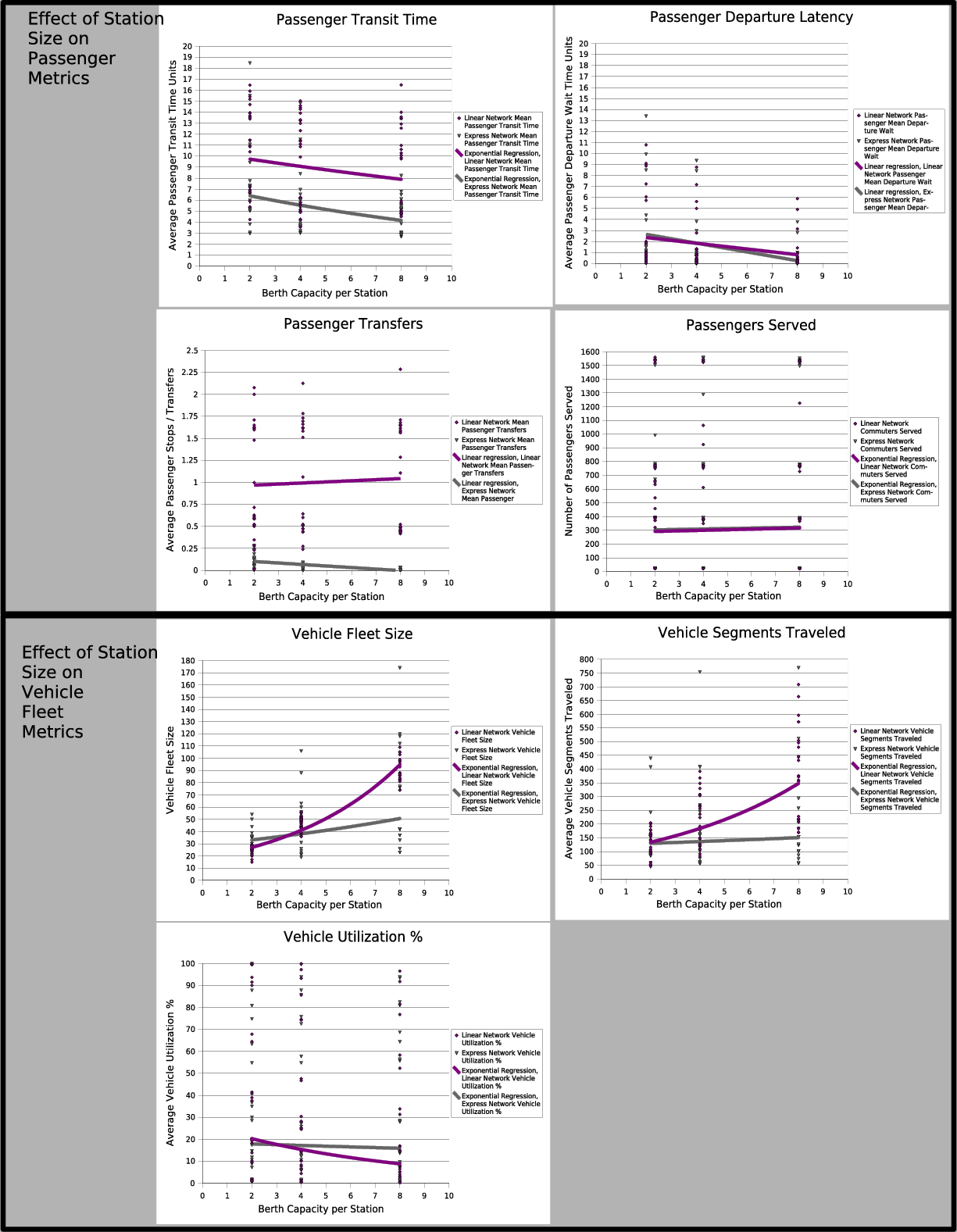
Figures 5.13 and 5.14 plot both the linear sequential routing scenarios and the express routing scenarios on the same set of factorial sensitivity plots for two other design factors (vehicle capacity and station capacity, respectively). A regression line through the data indicates the correlation between the design factor and the performance metric of interest averaged over all of the scenario conditions. A positive or negative slope indicates a correlation, a relatively horizontal regression line suggests that other factors dominate.
The top four charts in each set concern the impact of the design factors to passenger metrics, the bottom three charts affect the vehicle fleet performance.
 |
 |
The charts in Figure 5.13 show that vehicle capacity has little impact on passenger service for our optimized schedules. However, the type of routing used does have a profound impact on the average transit time and number of stops experienced by passengers. Allowing express routing to bypass stations can cut average transit time almost in half, while practically eliminating most stops and transfers.
The number of vehicles necessary to run a schedule and the amount of segments they run is also reduced. The reduction in segments comes about in large part because stops and transfers count as segments. While this may not be an accurate portrayal in terms of mileage saved, this could still represent savings of fuel and vehicle wear-and-tear, as braking and accelerating at a station can be every bit as taxing as cruising at a constant speed for many types of vehicles.
Figure 5.14 tells a similar story, though this time showing that increasing the number of vehicles that can dock at a station simultaneously can get passengers to their destinations more rapidly by easing congestion.
An additional curiosity shows that higher station berthing capacity can result in much a higher fleet size and operating costs in the linear sequential routing case which does not affect the express routing network much. This highlights some of the inefficiency of forcing vehicles to stop at every station along a route, especially when there's extra capacity to handle these stopovers.
This design factor analysis supports notion that, all inputs being equal and subject to our assumptions, an intelligently scheduled mass transit system designed around a larger quantity of smaller vehicles running direct point-to-point routes between offline stations could provide much faster passenger service while meeting and exceeding the fleet operational efficiency of more conventional systems.
Rowin Andruscavage 2007-05-22